 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Based Change-Point Detection and Region Localization for Spatio-Temporal Point Processes
Feb 04, 2026We study sequential change-point detection for spatio-temporal point processes, where actionable detection requires not only identifying when a distributional change occurs but also localizing where it manifests in space. While classical quickest change detection methods provide strong guarantees on detection delay and false-alarm rates, existing approaches for point-process data predominantly focus on temporal changes and do not explicitly infer affected spatial regions. We propose a likelihood-free, score-based detection framework that jointly estimates the change time and the change region in continuous space-time without assuming parametric knowledge of the pre- or post-change dynamics. The method leverages a localized and conditionally weighted Hyvärinen score to quantify event-level deviations from nominal behavior and aggregates these scores using a spatio-temporal CUSUM-type statistic over a prescribed class of spatial regions. Operating sequentially, the procedure outputs both a stopping time and an estimated change region, enabling real-time detection with spatial interpretability. We establish theoretical guarantees on false-alarm control, detection delay, and spatial localization accuracy, and demonstrate the effectiveness of the proposed approach through simulations and real-world spatio-temporal event data.
Training-Free Self-Correction for Multimodal Masked Diffusion Models
Feb 02, 2026Masked diffusion models have emerged as a powerful framework for text and multimodal generation. However, their sampling procedure updates multiple tokens simultaneously and treats generated tokens as immutable, which may lead to error accumulation when early mistakes cannot be revised. In this work, we revisit existing self-correction methods and identify limitations stemming from additional training requirements or reliance on misaligned likelihood estimates. We propose a training-free self-correction framework that exploits the inductive biases of pre-trained masked diffusion models. Without modifying model parameters or introducing auxiliary evaluators, our method significantly improves generation quality on text-to-image generation and multimodal understanding tasks with reduced sampling steps. Moreover, the proposed framework generalizes across different masked diffusion architectures, highlighting its robustness and practical applicability. Code can be found in https://github.com/huge123/FreeCorrection.
Alignment of Diffusion Model and Flow Matching for Text-to-Image Generation
Jan 31, 2026Diffusion models and flow matching have demonstrated remarkable success in text-to-image generation. While many existing alignment methods primarily focus on fine-tuning pre-trained generative models to maximize a given reward function, these approaches require extensive computational resources and may not generalize well across different objectives. In this work, we propose a novel alignment framework by leveraging the underlying nature of the alignment problem -- sampling from reward-weighted distributions -- and show that it applies to both diffusion models (via score guidance) and flow matching models (via velocity guidance). The score function (velocity field) required for the reward-weighted distribution can be decomposed into the pre-trained score (velocity field) plus a conditional expectation of the reward. For the alignment on the diffusion model, we identify a fundamental challenge: the adversarial nature of the guidance term can introduce undesirable artifacts in the generated images. Therefore, we propose a finetuning-free framework that trains a guidance network to estimate the conditional expectation of the reward. We achieve comparable performance to finetuning-based models with one-step generation with at least a 60% reduction in computational cost. For the alignment on flow matching, we propose a training-free framework that improves the generation quality without additional computational cost.
Corrected Samplers for Discrete Flow Models
Jan 30, 2026Discrete flow models (DFMs) have been proposed to learn the data distribution on a finite state space, offering a flexible framework as an alternative to discrete diffusion models. A line of recent work has studied samplers for discrete diffusion models, such as tau-leaping and Euler solver. However, these samplers require a large number of iterations to control discretization error, since the transition rates are frozen in time and evaluated at the initial state within each time interval. Moreover, theoretical results for these samplers often require boundedness conditions of the transition rate or they focus on a specific type of source distributions. To address those limitations, we establish non-asymptotic discretization error bounds for those samplers without any restriction on transition rates and source distributions, under the framework of discrete flow models. Furthermore, by analyzing a one-step lower bound of the Euler sampler, we propose two corrected samplers: \textit{time-corrected sampler} and \textit{location-corrected sampler}, which can reduce the discretization error of tau-leaping and Euler solver with almost no additional computational cost. We rigorously show that the location-corrected sampler has a lower iteration complexity than existing parallel samplers. We validate the effectiveness of the proposed method by demonstrating improved generation quality and reduced inference time on both simulation and text-to-image generation tasks. Code can be found in https://github.com/WanZhengyan/Corrected-Samplers-for-Discrete-Flow-Models.
Detecting Post-generation Edits to Watermarked LLM Outputs via Combinatorial Watermarking
Oct 02, 2025Watermarking has become a key technique for proprietary language models, enabling the distinction between AI-generated and human-written text. However, in many real-world scenarios, LLM-generated content may undergo post-generation edits, such as human revisions or even spoofing attacks, making it critical to detect and localize such modifications. In this work, we introduce a new task: detecting post-generation edits locally made to watermarked LLM outputs. To this end, we propose a combinatorial pattern-based watermarking framework, which partitions the vocabulary into disjoint subsets and embeds the watermark by enforcing a deterministic combinatorial pattern over these subsets during generation. We accompany the combinatorial watermark with a global statistic that can be used to detect the watermark. Furthermore, we design lightweight local statistics to flag and localize potential edits. We introduce two task-specific evaluation metrics, Type-I error rate and detection accuracy, and evaluate our method on open-source LLMs across a variety of editing scenarios, demonstrating strong empirical performance in edit localization.
Error Analysis of Discrete Flow with Generator Matching
Sep 26, 2025Discrete flow models offer a powerful framework for learning distributions over discrete state spaces and have demonstrated superior performance compared to the discrete diffusion model. However, their convergence properties and error analysis remain largely unexplored. In this work, we develop a unified framework grounded in stochastic calculus theory to systematically investigate the theoretical properties of discrete flow. Specifically, we derive the KL divergence of two path measures regarding two continuous-time Markov chains (CTMCs) with different transition rates by developing a novel Girsanov-type theorem, and provide a comprehensive analysis that encompasses the error arising from transition rate estimation and early stopping, where the first type of error has rarely been analyzed by existing works. Unlike discrete diffusion models, discrete flow incurs no truncation error caused by truncating the time horizon in the noising process. Building on generator matching and uniformization, we establish non-asymptotic error bounds for distribution estimation. Our results provide the first error analysis for discrete flow models.
Discrete Guidance Matching: Exact Guidance for Discrete Flow Matching
Sep 26, 2025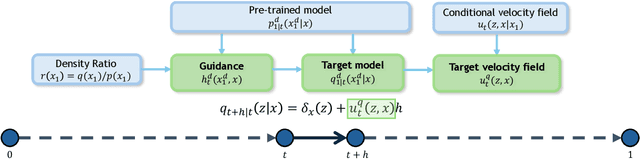

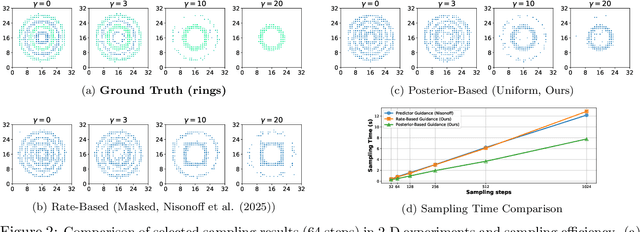
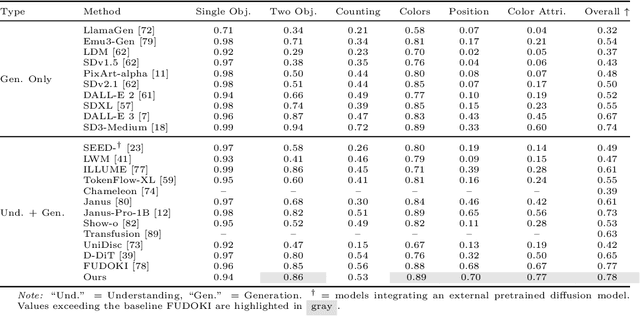
Guidance provides a simple and effective framework for posterior sampling by steering the generation process towards the desired distribution. When modeling discrete data, existing approaches mostly focus on guidance with the first-order Taylor approximation to improve the sampling efficiency. However, such an approximation is inappropriate in discrete state spaces since the approximation error could be large. A novel guidance framework for discrete data is proposed to address this problem: We derive the exact transition rate for the desired distribution given a learned discrete flow matching model, leading to guidance that only requires a single forward pass in each sampling step, significantly improving efficiency. This unified novel framework is general enough, encompassing existing guidance methods as special cases, and it can also be seamlessly applied to the masked diffusion model. We demonstrate the effectiveness of our proposed guidance on energy-guided simulations and preference alignment on text-to-image generation and multimodal understanding tasks. The code is available through https://github.com/WanZhengyan/Discrete-Guidance-Matching/tree/main.
Recurrent Neural Goodness-of-Fit Test for Time Series
Oct 17, 2024



Time series data are crucial across diverse domains such as finance and healthcare, where accurate forecasting and decision-making rely on advanced modeling techniques. While generative models have shown great promise in capturing the intricate dynamics inherent in time series, evaluating their performance remains a major challenge. Traditional evaluation metrics fall short due to the temporal dependencies and potential high dimensionality of the features. In this paper, we propose the REcurrent NeurAL (RENAL) Goodness-of-Fit test, a novel and statistically rigorous framework for evaluating generative time series models. By leveraging recurrent neural networks, we transform the time series into conditionally independent data pairs, enabling the application of a chi-square-based goodness-of-fit test to the temporal dependencies within the data. This approach offers a robust, theoretically grounded solution for assessing the quality of generative models, particularly in settings with limited time sequences. We demonstrate the efficacy of our method across both synthetic and real-world datasets, outperforming existing methods in terms of reliability and accuracy. Our method fills a critical gap in the evaluation of time series generative models, offering a tool that is both practical and adaptable to high-stakes applications.
Transfer Learning for Diffusion Models
May 28, 2024



Diffusion models, a specific type of generative model, have achieved unprecedented performance in recent years and consistently produce high-quality synthetic samples. A critical prerequisite for their notable success lies in the presence of a substantial number of training samples, which can be impractical in real-world applications due to high collection costs or associated risks. Consequently, various finetuning and regularization approaches have been proposed to transfer knowledge from existing pre-trained models to specific target domains with limited data. This paper introduces the Transfer Guided Diffusion Process (TGDP), a novel approach distinct from conventional finetuning and regularization methods. We prove that the optimal diffusion model for the target domain integrates pre-trained diffusion models on the source domain with additional guidance from a domain classifier. We further extend TGDP to a conditional version for modeling the joint distribution of data and its corresponding labels, together with two additional regularization terms to enhance the model performance. We validate the effectiveness of TGDP on Gaussian mixture simulations and on real electrocardiogram (ECG) datasets.
$e^{\text{RPCA}}$: Robust Principal Component Analysis for Exponential Family Distributions
Oct 30, 2023Robust Principal Component Analysis (RPCA) is a widely used method for recovering low-rank structure from data matrices corrupted by significant and sparse outliers. These corruptions may arise from occlusions, malicious tampering, or other causes for anomalies, and the joint identification of such corruptions with low-rank background is critical for process monitoring and diagnosis. However, existing RPCA methods and their extensions largely do not account for the underlying probabilistic distribution for the data matrices, which in many applications are known and can be highly non-Gaussian. We thus propose a new method called Robust Principal Component Analysis for Exponential Family distributions ($e^{\text{RPCA}}$), which can perform the desired decomposition into low-rank and sparse matrices when such a distribution falls within the exponential family. We present a novel alternating direction method of multiplier optimization algorithm for efficient $e^{\text{RPCA}}$ decomposition. The effectiveness of $e^{\text{RPCA}}$ is then demonstrated in two applications: the first for steel sheet defect detection, and the second for crime activity monitoring in the Atlanta metropolitan area.